Análisis de Demanda Eléctrica ANDE
Plataforma completa para análisis energético con: - Carga automatizada de datos desde Excel - Procesamiento estadístico de series temporales - Visualizaciones interactivas con marcadores estacionales - Sistema de pruebas automatizadas - Gestión de dependencias con uv - Generación de reportes gráficos profesionales - Forecasting de demanda eléctrica usando métodos tradicionales y modelos neuronales

Detalles Técnicos
Multiple Series Plot
# Ande_Demanda_de_Potencia_Mensual
Datos mensuales de la demanda de potencia máxima por mes, Paraguay.
# Jupyter notebook converted to Python script.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# Leer el archivo Excel
df = pd.read_excel('demanda2.xlsx')
# Seleccionar las columnas relevantes (Año y meses)
columnas_meses = ['Año', 'Enero', 'Febrero', 'Marzo', 'Abril', 'Mayo', 'Junio', 'Julio', 'Agosto', 'Septiembre', 'Octubre', 'Noviembre', 'Diciembre']
df_meses = df[columnas_meses]
# Reorganizar el DataFrame para ser compatible con Seaborn
df_meses_melted = pd.melt(df_meses, id_vars='Año', var_name='Mes', value_name='KWh')
# Ordenar los meses correctamente
orden_meses = ['Enero', 'Febrero', 'Marzo', 'Abril', 'Mayo', 'Junio', 'Julio', 'Agosto', 'Septiembre', 'Octubre', 'Noviembre', 'Diciembre']
df_meses_melted['Mes'] = pd.Categorical(df_meses_melted['Mes'], categories=orden_meses, ordered=True)
# Configurar tema y estilo de Seaborn
sns.set_theme(style="white")
# Plot cada serie temporal de años en su propia faceta
g = sns.relplot(
data=df_meses_melted,
x="Mes", y="KWh", col="Año", hue="Año",
kind="line", palette="crest", linewidth=4, zorder=5,
col_wrap=3, height=5, aspect=2, legend=False
)
# Personalizar cada subplot
for año, ax in g.axes_dict.items():
ax.text(0.9, 0.90, str(año), transform=ax.transAxes, fontweight="bold",
bbox=dict(facecolor='white', edgecolor='black', boxstyle='round,pad=0.1'))
sns.lineplot(
data=df_meses_melted, x="Mes", y="KWh", units="Año",
estimator=None, color=".7", linewidth=1, ax=ax
)
ax.tick_params(axis='x', rotation=90)
ax.set_xticks(range(len(orden_meses)))
ax.set_xticklabels(orden_meses)
ax.axvline(x=2, color='red', linestyle='--', linewidth=0.8, label='Marzo')
ax.axvline(x=8, color='red', linestyle='--', linewidth=0.8, label='Septiembre')
datos_año = df_meses_melted[df_meses_melted['Año'] == año]
promedio_anual = datos_año['KWh'].mean()
ax.plot(datos_año['Mes'], [promedio_anual] * len(datos_año), color='green', linestyle='--', linewidth=1,
label=f'Promedio Anual MW: {promedio_anual:.0f}')
for idx in range(len(orden_meses)):
ax.axvline(x=idx, color='black', linestyle='--', alpha=0.3, linewidth=0.2)
ax.legend()
ax.patch.set_edgecolor('black')
ax.patch.set_linewidth(1)
ax.set_xlim(-0.5, len(orden_meses) - 0.5)
g.set_titles("")
g.set_axis_labels("", "MW")
g.tight_layout()
plt.show()
g.savefig("grafico_demandaactual.png", dpi=200, bbox_inches="tight")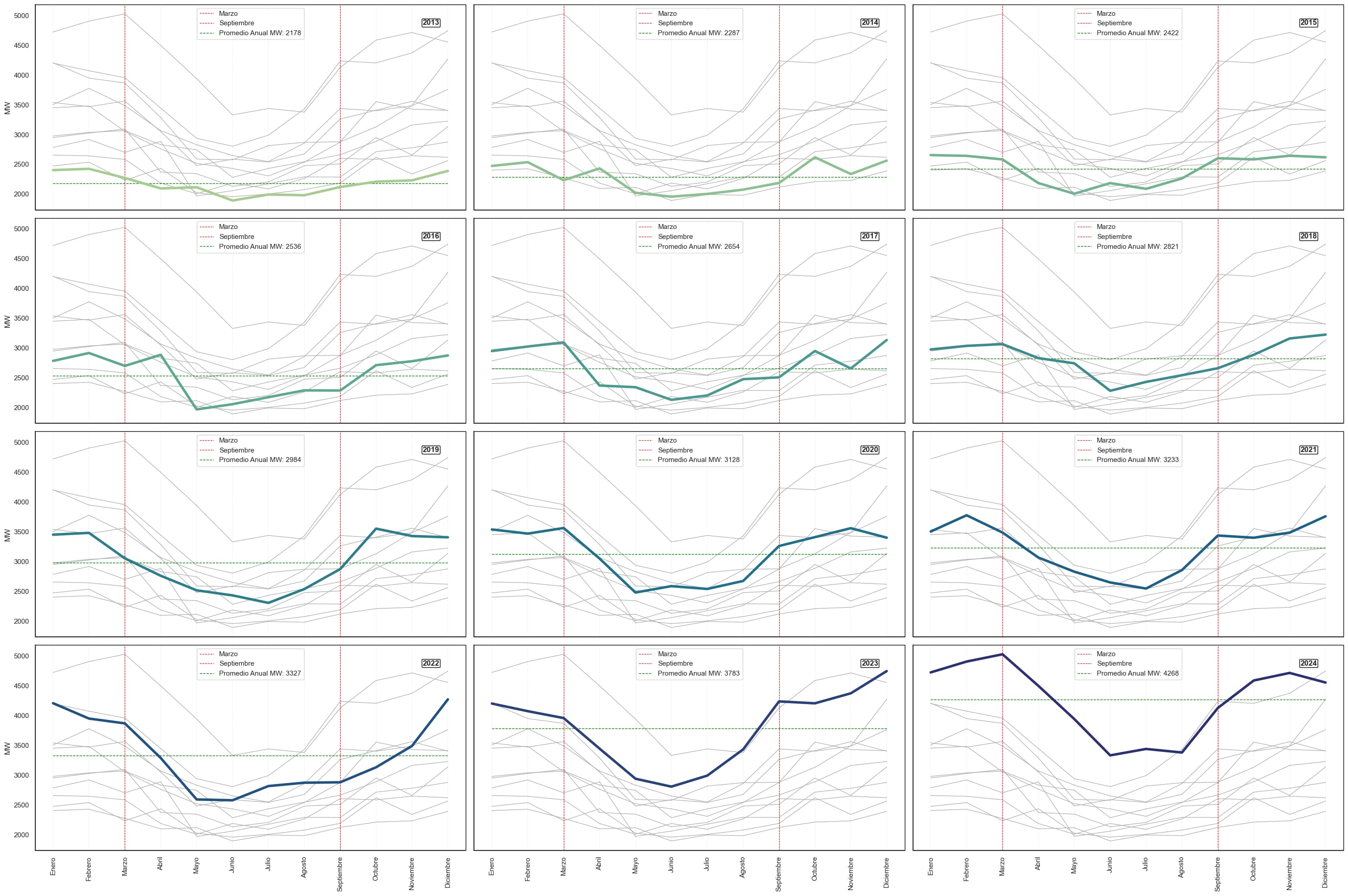
Neuronal Forecasting
import logging
import pandas as pd
from utilsforecast.plotting import plot_series
from neuralforecast import NeuralForecast
from neuralforecast.models import NBEATS, NHITS
from neuralforecast.utils import AirPassengersDF
logging.getLogger('pytorch_lightning').setLevel(logging.ERROR)
# Cargar y transformar los datos
df2 = pd.read_excel('demanda2.xlsx')
meses_es_en = {
'Enero': 'January', 'Febrero': 'February', 'Marzo': 'March', 'Abril': 'April',
'Mayo': 'May', 'Junio': 'June', 'Julio': 'July', 'Agosto': 'August',
'Septiembre': 'September', 'Octubre': 'October', 'Noviembre': 'November', 'Diciembre': 'December'
}
df_melted = df2.melt(id_vars=['Año'], var_name='Mes', value_name='y')
df_melted['Mes'] = df_melted['Mes'].map(meses_es_en)
df_melted['ds'] = pd.to_datetime(df_melted['Año'].astype(str) + '-' + df_melted['Mes'], format='%Y-%B')
df_final = df_melted[['ds', 'y']].sort_values('ds').reset_index(drop=True)
# Agregar columna de identificador único
df_final['unique_id'] = 'ts_1'
# Dividir datos en entrenamiento y prueba (últimas 12 entradas para prueba)
train_df = df_final.iloc[:-12]
test_df = df_final.iloc[-12:]
horizonte = len(test_df)
# Configurar y ajustar modelos NBEATS y NHITS
modelos = [
NBEATS(input_size=2 * horizonte, h=horizonte, max_steps=100, enable_progress_bar=False),
NHITS(input_size=2 * horizonte, h=horizonte, max_steps=100, enable_progress_bar=False)
]
nf = NeuralForecast(models=modelos, freq='ME')
nf.fit(df=train_df)
pronostico_df = nf.predict()
# Graficar la serie de entrenamiento y los pronósticos
plot_series(train_df, pronostico_df)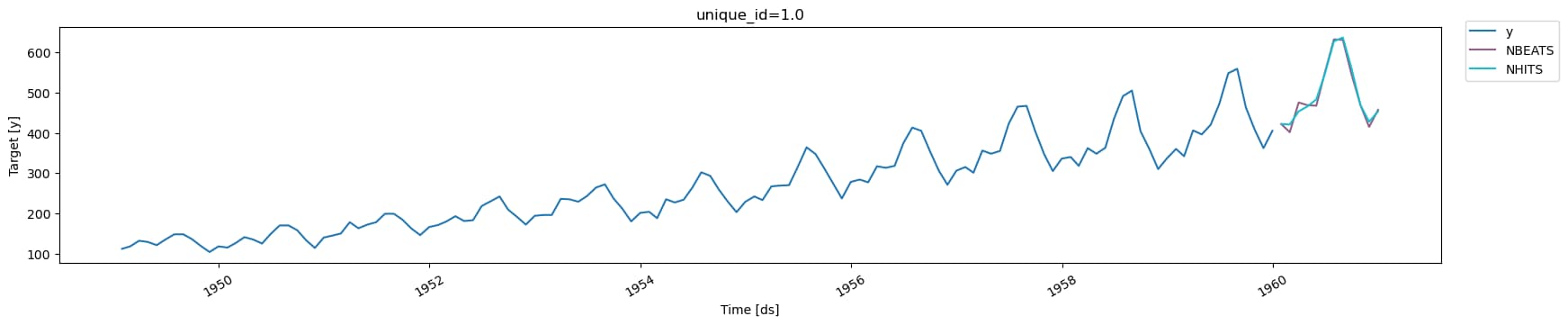
StatsForecast Model
import pandas as pd
from statsforecast import StatsForecast
from statsforecast.models import AutoARIMA
import matplotlib.pyplot as plt
# Cargar y transformar los datos
df2 = pd.read_excel('demanda2.xlsx')
meses_es_en = {
'Enero': 'January', 'Febrero': 'February', 'Marzo': 'March', 'Abril': 'April',
'Mayo': 'May', 'Junio': 'June', 'Julio': 'July', 'Agosto': 'August',
'Septiembre': 'September', 'Octubre': 'October', 'Noviembre': 'November', 'Diciembre': 'December'
}
df_melted = df2.melt(id_vars=['Año'], var_name='Mes', value_name='y')
df_melted['Mes'] = df_melted['Mes'].map(meses_es_en)
df_melted['ds'] = pd.to_datetime(df_melted['Año'].astype(str) + '-' + df_melted['Mes'], format='%Y-%B')
df_final = df_melted[['ds', 'y']].sort_values('ds').reset_index(drop=True)
df_final['unique_id'] = 1
sf = StatsForecast(
models=[AutoARIMA(season_length=12)],
freq='ME'
)
sf.fit(df_final)
forecast = sf.predict(h=12, level=[95])
plt.figure(figsize=(10, 6))
plt.plot(df_final['ds'], df_final['y'], label='Datos históricos')
plt.plot(forecast['ds'], forecast['AutoARIMA'], label='Predicción', color='orange')
plt.fill_between(forecast['ds'], forecast['AutoARIMA-lo-95'], forecast['AutoARIMA-hi-95'], color='orange', alpha=0.3, label='Intervalo de confianza 95%')
plt.xlabel('Fecha')
plt.ylabel('Demanda de Potencia')
plt.title('Predicción de Demanda de Potencia Mensual')
plt.legend()
plt.show()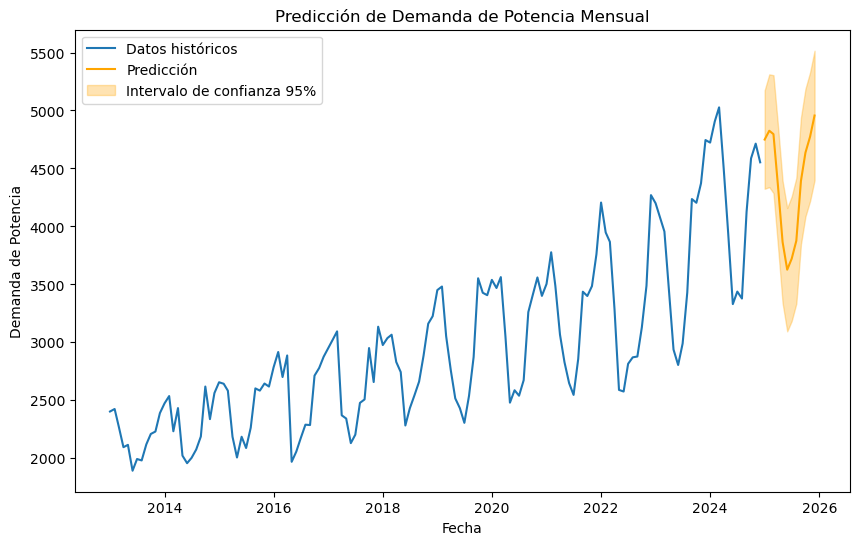
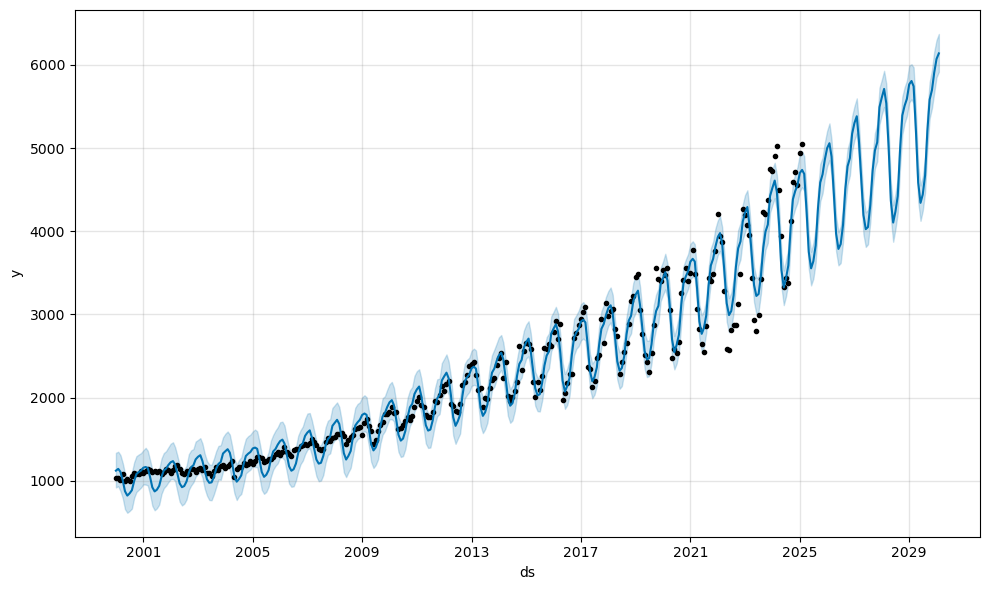
Prophet Model
import pandas as pd
from prophet import Prophet
# Cargar datos
df2 = pd.read_excel('demanda2.xlsx')
# Diccionario para traducir los nombres de los meses de español a inglés
meses_es_en = {'Enero': 'January', 'Febrero': 'February', 'Marzo': 'March', 'Abril': 'April', 'Mayo': 'May', 'Junio': 'June', 'Julio': 'July', 'Agosto': 'August', 'Septiembre': 'September', 'Octubre': 'October', 'Noviembre': 'November', 'Diciembre': 'December'}
# Convertir el DataFrame al formato deseado
df_melted = df2.melt(id_vars=['Año'], var_name='Mes', value_name='y')
# Traducir los meses
df_melted['Mes'] = df_melted['Mes'].map(meses_es_en)
# Crear la columna de fechas
df_melted['ds'] = pd.to_datetime(df_melted['Año'].astype(str) + '-' + df_melted['Mes'], format='%Y-%B')
# Seleccionar solo las columnas necesarias
df_final = df_melted[['ds', 'y']]
# Ordenar por fecha
df_final = df_final.sort_values(by='ds').reset_index(drop=True)
# Mostrar resultado
print(df_final.head())
m = Prophet()
m.fit(df_final)
future = m.make_future_dataframe(50, freq='MS')
forecast = m.predict(future)
fig = m.plot(forecast)
m = Prophet(seasonality_mode='multiplicative')
m.fit(df_final)
forecast = m.predict(future)
fig = m.plot(forecast)